
最近,在苹果2024秋季新品发布会上,苹果发布了有史以来最大的iPhone。而同一天开发布会的华为,重磅发布了首款三折屏手机。
智能手机越做越大,是为了装下大模型吗?
回顾2022年,自从ChatGPT/GPT大语言模型发布以来,大模型一直在持续增大,因为业界相信扩展定律(Scaling Law),相信能通过大数据+大参数打造更大的模型从而拥有更高的智能。
当时不可一世的GPT-3的训练参数量级已经来到了175B,但在参数量这个赛道上,它依旧不是王者。更甚者如Luminous 的200B、Gopher的280B、PaLM的540B。
因此在当时,几乎没有个人PC能够承载大模型的运算参数。可以说当时的大模型仅属于硬件俱乐部的宠儿,个人想使用大模型,除非搭建Nvidia计算卡集群,如此苛刻的条件下,国内大模型厂商几乎是要靠不断砸钱才能维持运转。
如今发展到2024年,大模型世界发生了一些新的变化——一些大模型开始把自己越做越小。
2024年以来,微软、谷歌、苹果相继发布轻量化的AI大模型,以满足个人电脑、手机等智能终端设备的部署要求。
究其原因:
- 从需求侧来看
随着生成式AI技术的飞速发展,其广泛应用确实带来了前所未有的计算挑战和成本问题。云端推理虽然提供了强大的计算能力和数据存储优势,但高昂的运营成本和数据传输延迟成为了不可忽视的障碍。在这种背景下,将部分处理任务转移到边缘终端成为了一个重要的解决方案。
此外,大量场合无法联网,以及规避数据上网所带来的隐私与安全隐患等,都是来自用户对于端侧模型的强烈诉求。
- 从技术侧来看
小参数模型在推理领域不断优化,发展极其迅速。为什么参数量小的模型,依旧保持了很好的泛化能力呢?这是因为Transformer不仅是另一个神经网络,而是一个极具通用性的“差分计算机”。它通过前向和后向传播进行自我调整,能够高效处理复杂任务。
Transformer的扩展性是AI领域的重大突破,使得大规模模型成为可能,但同时也可以通过蒸馏、剪枝等技术,能够将大模型的能力压缩到更小的模型中,实现更高效的认知处理,甚至1~10亿参数的小模型就能完成复杂任务。
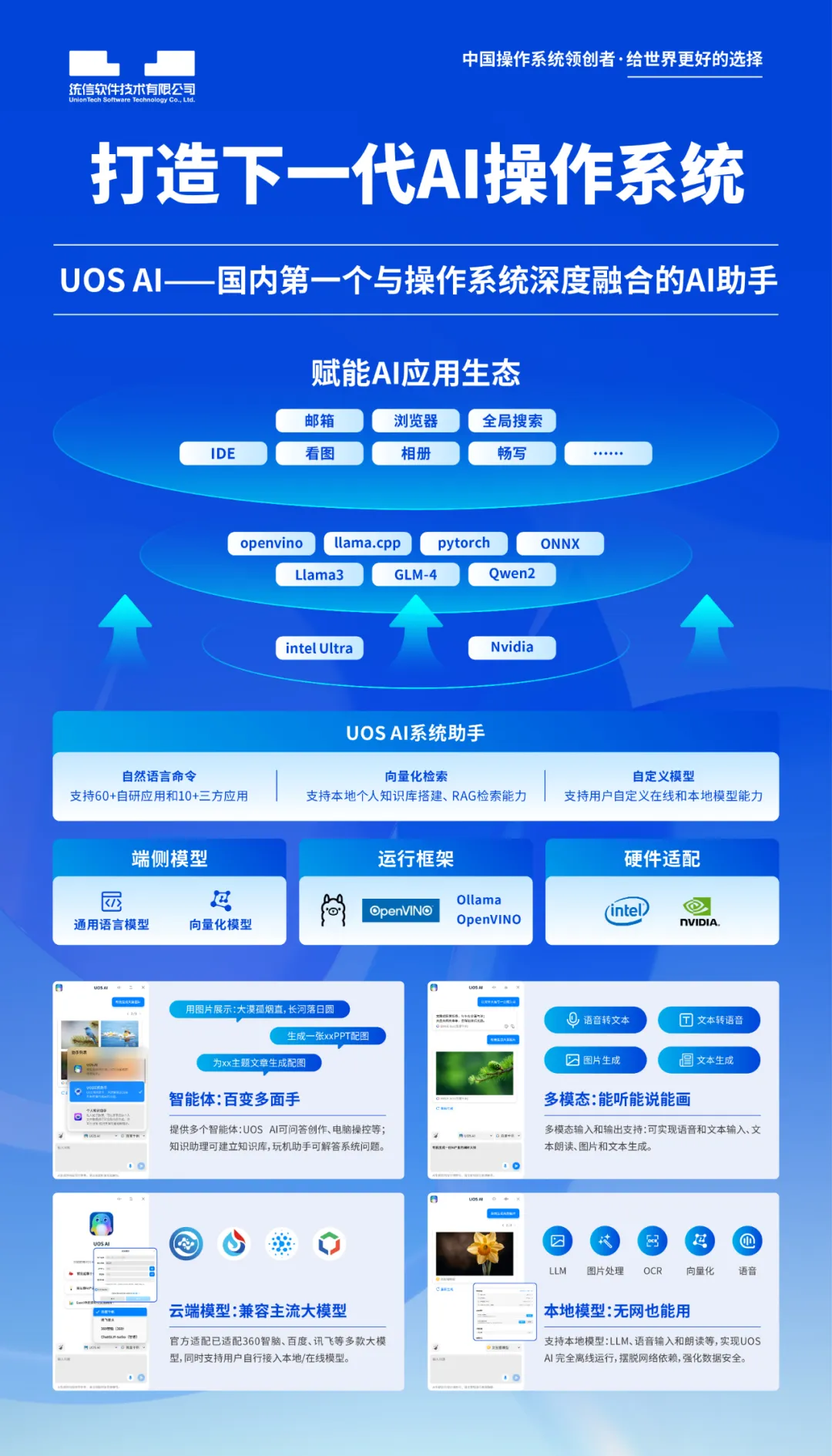
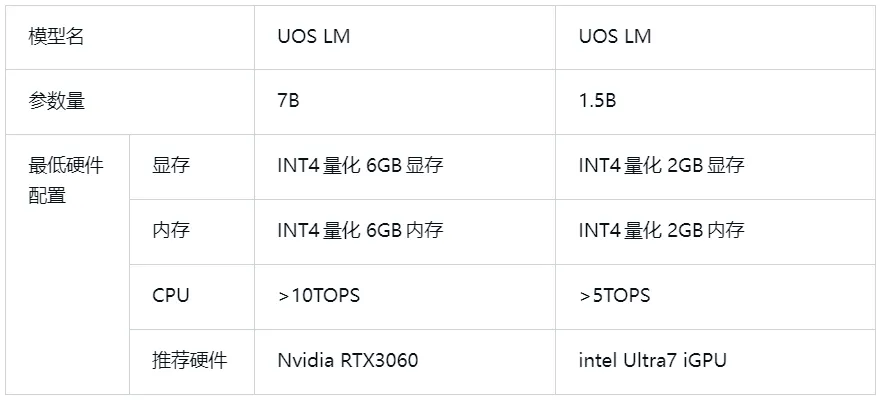
这也是为什么,今年8月统信软件发布的中国首款操作系统级端侧模型“UOS LM”(又名“统信有容”),参数量定义在1.5B和7B两个区间,这样的模型既能保持原始模型优秀的泛化能力,同时小参数加上量化技术后,可以把模型压缩至1G以下,尽最大可能节约用户空间,使用户流畅体验端侧模型能力成为可能。
更流畅的使用体验
UOS LM作为统信软件UOS AI系统级人工智能体系中的重要组成部分,其优势不仅体现在强大的自然语言处理能力上,更在于它如何智能地理解和执行用户的指令。
◈精准意图识别
传统自然语言处理方法在解析复杂或模糊指令时往往力不从心,而UOS LM则采用了先进的深度学习算法和意图识别技术。
通过不断优化模型结构和训练数据,UOS LM能够更准确地捕捉用户输入中的潜在意图,甚至能识别出细微的情感变化和语气差异,从而提供更加个性化的回应。
◈向量化RAG检索
在向量化知识库和RAG(Retrieval Augmented Generation)检索增强技术的加持下,UOS LM能够在庞大的知识库中迅速找到与用户问题最相关的信息。
这一技术通过计算用户输入与系统指令描述之间的向量相似度,实现了对系统指令的精确匹配与执行。这种机制不仅提高了操作的准确性,还显著缩短了响应时间,让用户体验更加流畅。
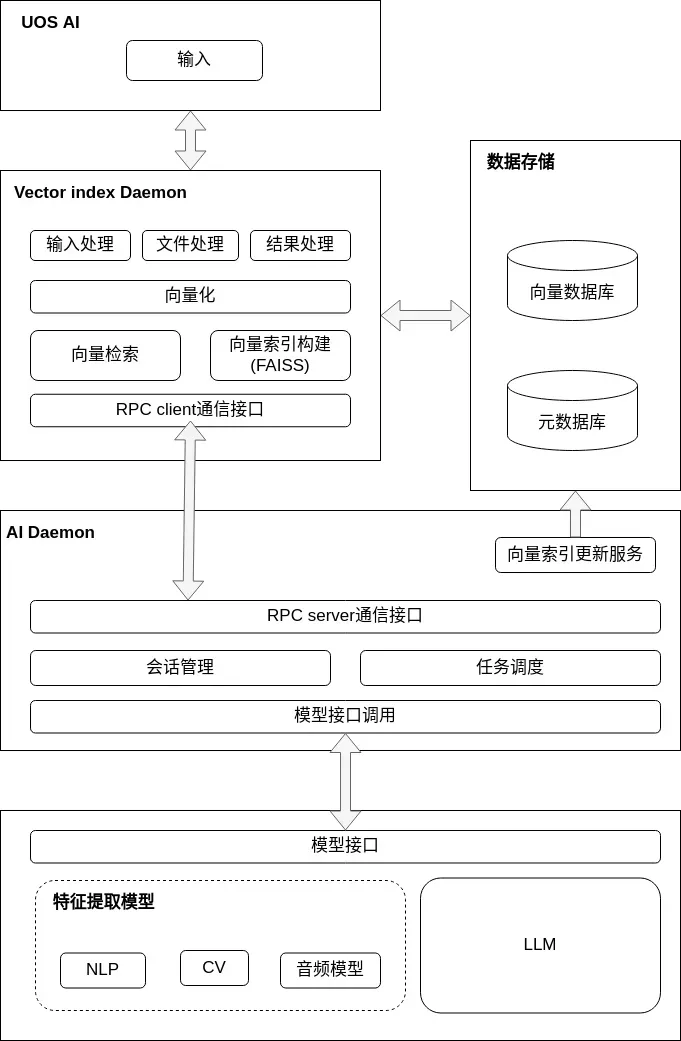
◈动态Prompts生成
为了充分利用大模型的强大能力,UOS LM在用户提出问题后,会先在本地知识库中进行检索。通过智能地结合检索到的信息与用户原始问题,UOS LM能够生成更加全面和精确的prompts,并输入到大模型中进行处理。
这种动态生成prompts的方式,不仅提高了输出的准确性和相关性,还使得大模型能够更好地理解并处理特定领域的高度专业化知识或最新信息。
可以说,UOS LM比你更知道你电脑里面发生的事情。
更智能的加速框架
除了精准捕捉意图,用户具体要执行的AI任务也可以在加速框架中进行批量并行封装处理,从而可以支持多应用智能的并发处理,大大提高智能特性的整体运行效率。
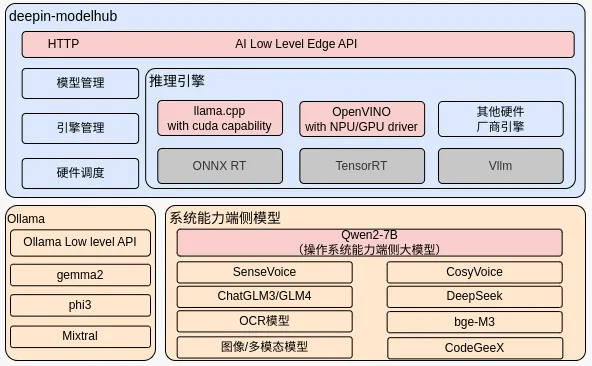
针对多应用智能的并发处理需求,UOS LM的加速框架支持批量并行封装处理。这意味着多个AI任务可以同时在系统中运行,而不会相互干扰或影响性能。这种批量并行处理的方式,不仅提高了任务处理的速度,还使得系统资源得到了更加合理的利用。
同时,通过deepin-modelhub模型管理框架,统信UOS赋予了用户加载个性化AI模型的能力。这项技术可以让用户加载属于自己的模型,技术路线上兼容了llama.cpp和OpenVINO的生态,用户除了可以在deepin-modelhub里运行UOS LM大语言模型之外,还可以自己添加llama 3.1、phi-3、gemma2、qwen2等模型。
这些模型可不是只能躺在命令行里提供指令,而是可以直接链接UOS AI助手,也许有一天用户可以自己手动训练一个专属模型,直接享受端侧模型带来的便利,最大效能发挥机器硬件算力带来的魅力。
更包容的硬件策略
在UOS LM端侧模型中,我们对硬件策略的选择主要基于四个方面,分别是性能、能耗比、可靠性、安全性。
硬件性能是端侧模型考虑的首要因素,2024年统计的全球知名大模型需要的算力情况可知,各路知名大模型对硬件的要求至少都是A100或者H100这样的硬件,算力也从130 TFLOP/s到1000 TFLOP/s不等。
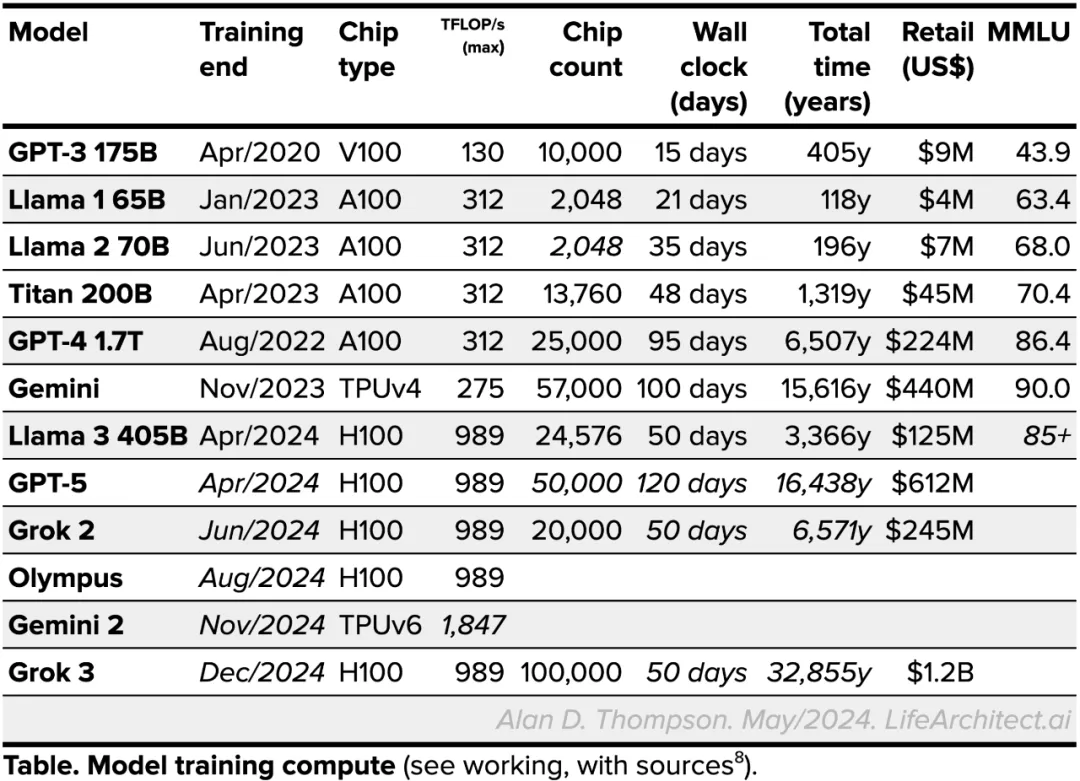
UOS LM的端侧模型与硬件做了深入绑定,经过了各项深入的性能测试和平台功能验证,UOS LM在端侧的硬件性能要求更加贴合用户实际情况:
UOS LM模型加载框架里会提供最佳的运行方式,常见情况下:
- 若用户有支持cuda的Nvidia显卡,系统可以提供cuda加速版本的加速方式;
- 若用户没有Nvidia显卡,取而代之的是Intel的Ultra芯片,系统也可以提供Ultra的OpenVINO加速方案;
- 最后若当前仅有通用CPU,不具备AI PC硬件要求,系统也可以提供基于通用CPU的模型推理方式。
支持高效AI处理的边缘终端具有领先能效,能以低能耗运行生成式AI模型,且有助于云服务提供商降低数据中心能耗,实现环境和可持续发展目标,特别是在处理和数据传输相结合时,能耗成本差异明显。
统信软件正将AI能力变成桌面操作系统的基础服务,统信UOS也成为唯一与国际主流操作系统在AI产品理念、技术路线齐头并进的中国操作系统。

无论是UOS AI,还是华为、微软、苹果,它们的加入让操作系统不再仅仅是软件运行的平台,而是集成了强大AI能力的智能化平台,这种转变将极大地扩展操作系统的应用场景和功能边界。未来,我们将携手更多终端厂商,为用户带来更流畅、更智能的操作系统使用体验!
©统信软件技术有限公司。访问者可将本网站提供的内容或服务用于个人学习、研究或欣赏,以及其他非商业性或非盈利性用途,但同时应遵守著作权法及其他相关法律的规定,不得侵犯本网站及相关权利人的合法权利。除此以外,将本网站任何内容或服务进行转载,须备注:该文档出自【faq.uniontech.com】统信软件知识分享平台。否则统信软件将追究相关版权责任。

